AI landscape - state of the art
the expert behaviour self learning :
- 200 user exchanges 50 quality patterns 2 weeks of usage (averages) shown a change in agent behaviour
- 1000 user exchanges 200 quality patterns more or less 2 month of running shown expert corrections drop dramatically, accuracy of answer is close to 80%
Day 1 model propose generic solution and knowledge on main pinciples
Day 60 model is able to provide an accurate methodology as an expert!
main points
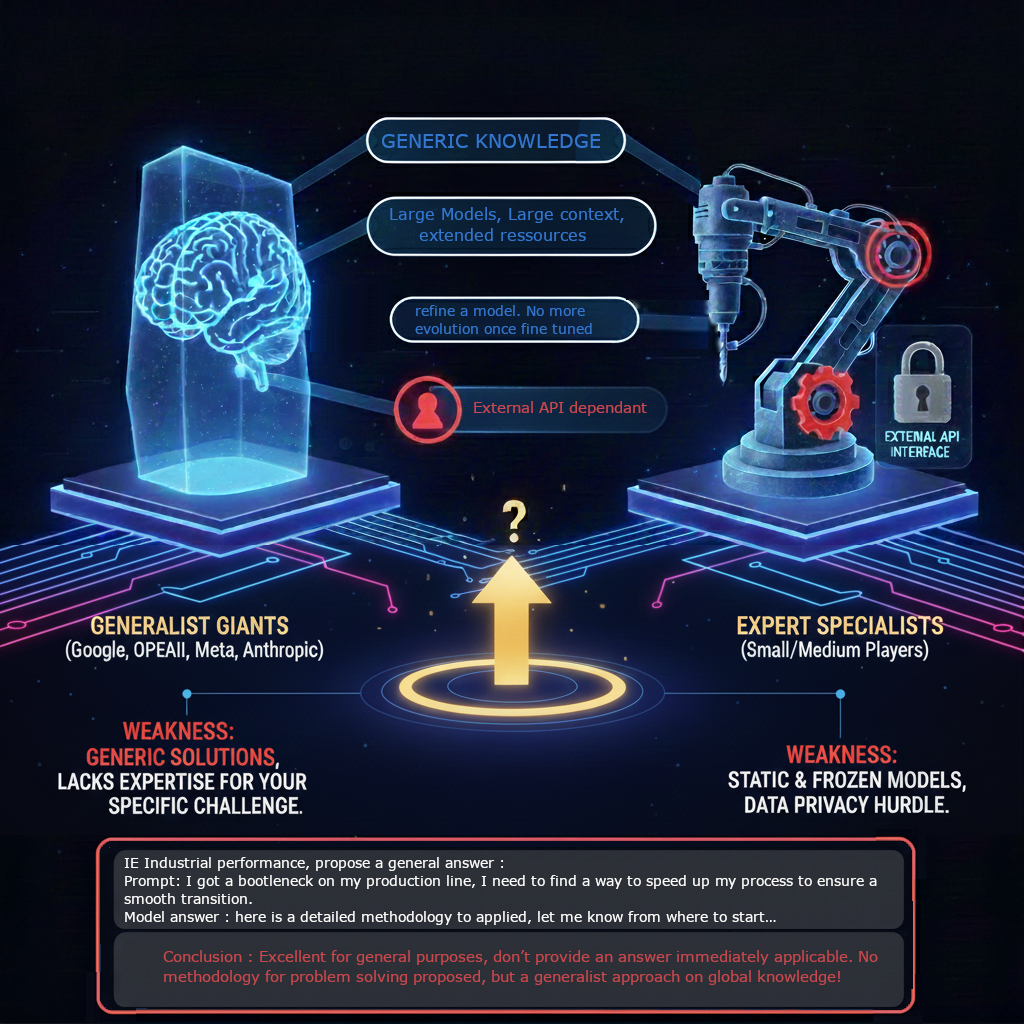
- 2 main players categories on the market :
big players and Small / medium actors - Great assistant, but far from an efficient Expert
- How to have a solution to train and use expert at same time?
- How to have a self eveolving system?
- Different expertise but same way of thinking process (measure, identify, incrental implement)
- Expert = knowledge + pattern of thinking
- new era off Agentic agent open in 2026.
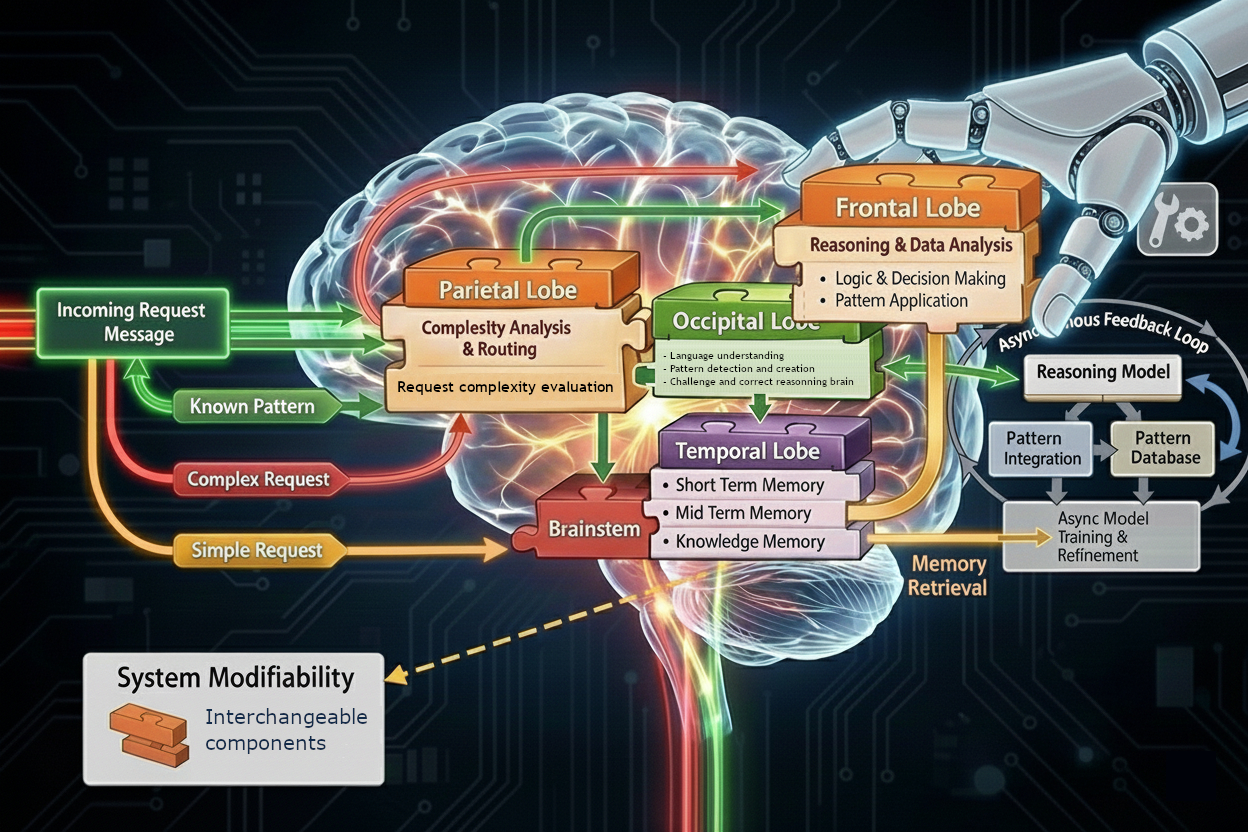
We were able to implement a cascade of models
(from 4b up to 81B parameters) with dedicated functions for each ones. - a full model of 70b parameters is dedicated
only to identify and formalized the pattern of thinking of the request sent,
validate and integrate user feedback,
correct it and certify this way of thinking,
under control and validation of human expert! - dedicated reasoning model is constrain to apply it by our agent orchestrator,
on verification loop is applied and methodology is checked for each answer,
once a complexity agent detect the needs - periodically (weekly or daily at the beginning, monthly later,
an integration of VALID and CERTIFIED partetern in the model weitgh are applied,
to integrate natively the new pattern inside the reasoning model. - Expert = knowledge + pattern of thinking